Python爬虫学习笔记(一)Scrapy框架实战
写在前面
这篇博客来记录学习Python爬虫
主要是为了应付数据可视化这门课程而写,虽然标题有(一),但可能不会有(二)了
毕竟本人不是走这方面路子的(逃
什么是Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
以上内容引用自初窥Scrapy——Scarpy 0.24.1 文档
Scrapy的框架如下
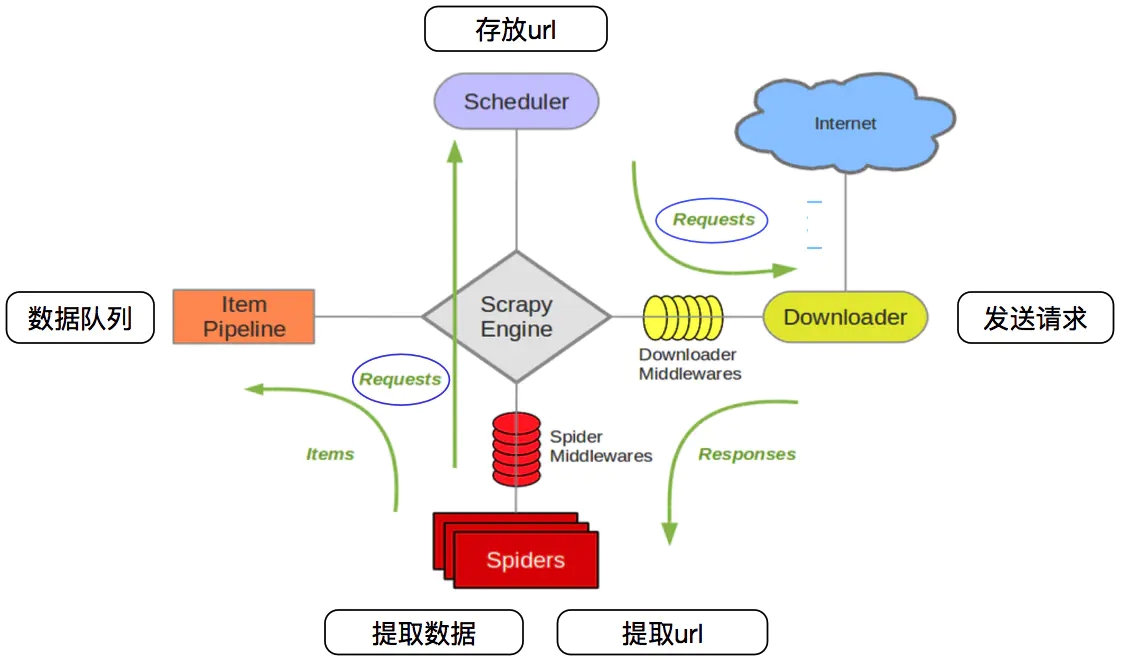
-
crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
-
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
-
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
-
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
-
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
-
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
-
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
如何安装
首先,确保你的计算机里已经安装好了Python(2.7以上)
先从这里下载对应系统版本的twisted文件(如Twisted-xxx-win_amd64.whl),用pip安装它。(否则安装Scrapy会出错)
接着在终端输入pip install scrapy即可安装成功
注:Python3以上的版本可能是pip3
开始使用
以下内容以爬取斗鱼主播为例
创建项目
在你要存放项目的位置开启终端,并键入以下命令
1 | scrapy startproject <project name> |
即可在当前目录创建名为<project name>的项目,出现如下图提示即表示创建成功
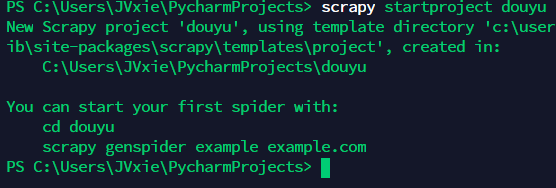
这里<projcet name>取douyu,创建完后会自动生成一个名为douyu的文件夹,目录如下
1 | douyu/ |
scrapy.cfg:项目的配置文件items.py:存放容器的文件middlewares.py:下载中间件和Spider中间件的定义和实现文件pipelines.py:管道的定义和实现文件,用于数据清洗、存储及验证settings.py:项目的设置文件spiders/:存放爬虫代码的目录
创建一个爬虫
终端进入到项目中的douyu目录,并键入以下命令
1 | scrapy genspider <spider name> <domain> |
这里的<spider name>指的是爬虫文件的名字,可以自定义,<domain>指的是要爬取的网站
即可在spider目录下新建一个爬虫文件,出现如下图提示即代表创建成功

创建好的douyu_spider.py应该长这样
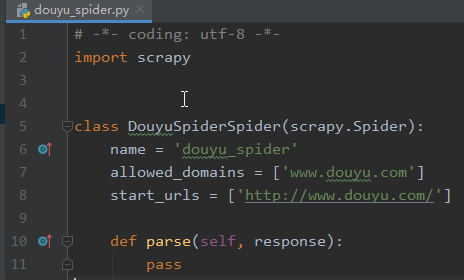
其中包含的属性分别代表
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。allowed_domains:包含了Sprider爬取的域名,防止爬取到其他域名start_urls:包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一, 后续的URL则从初始的URL获取到的数据中提取parse():将调用的方法,用于处理为每个请求下载的响应。响应参数是的实例TextResponse它保存页面内容,并有进一步有用的方法来处理它
运行爬虫
终端回到项目的顶级目录,并键入以下命令
1 | scrapy crawl <spider name> |
注意:这里的spider name指的是爬虫文件里的name,而非爬虫文件名
出现如下图的提示信息即代表执行爬虫成功

这些都只是基础的安装运行,这样的爬虫并无任何作用,接下来要进行更深层的实战
实战
这个实战爬取的是斗鱼上颜值主播(绿色健康)的相关信息,如封面、昵称
首先我们需要获取到能够爬取的URL,这里可以用Chrome自带的开发者工具切换到手机端获取
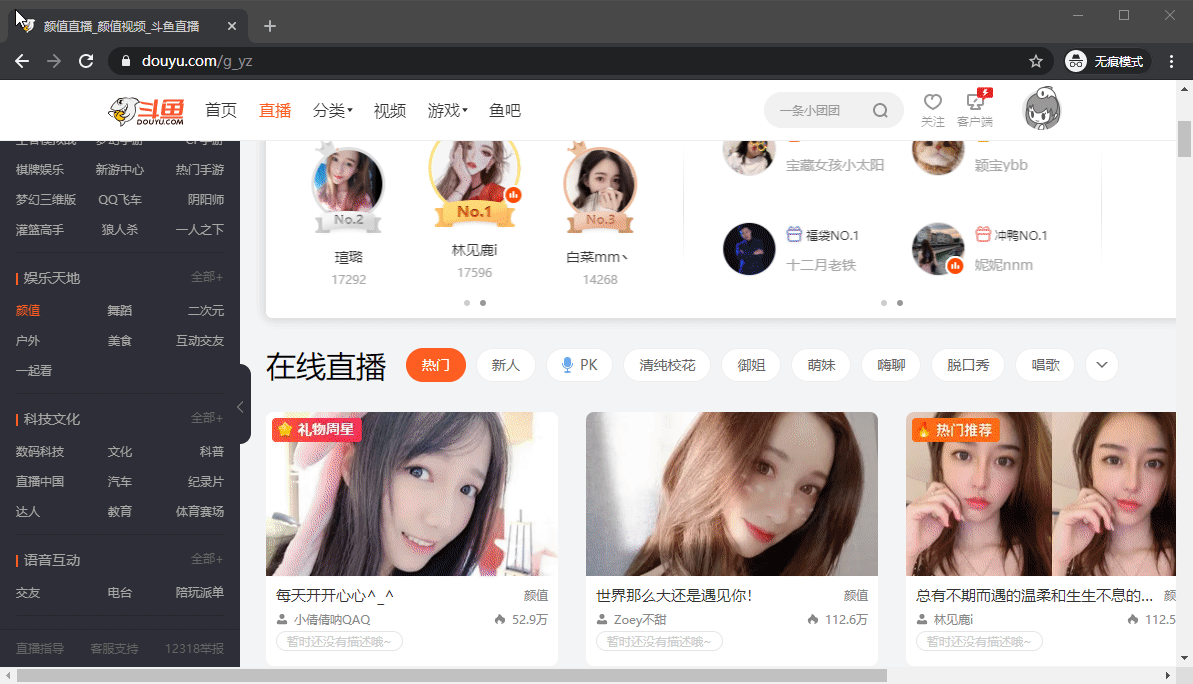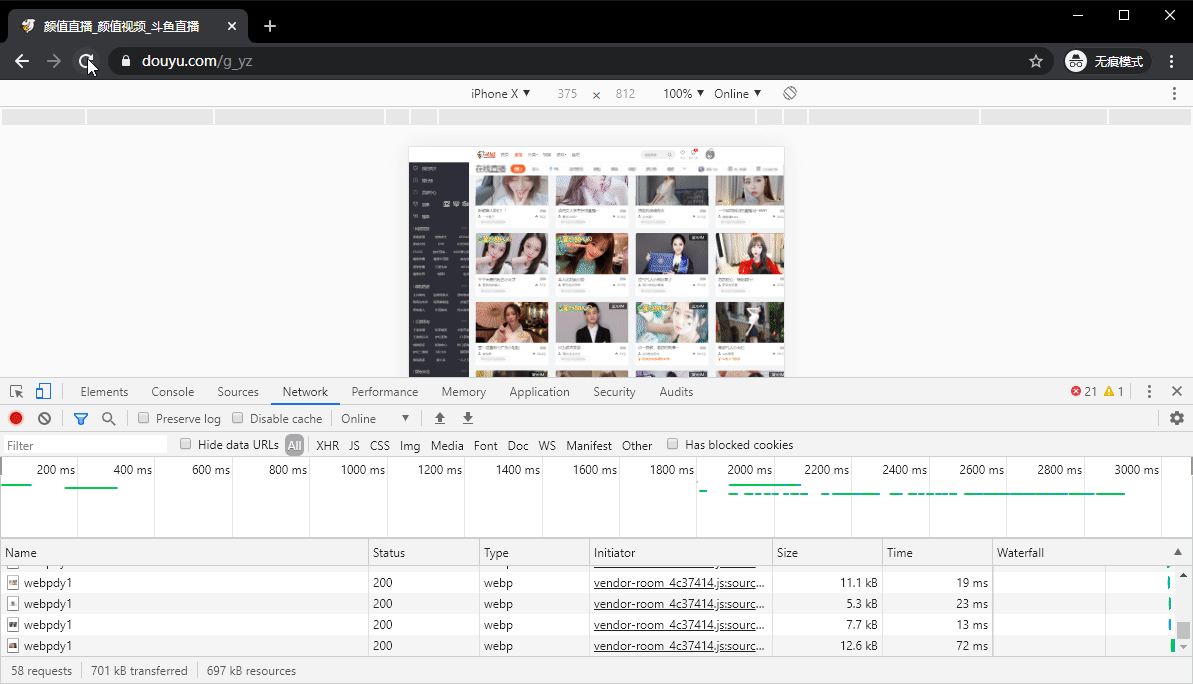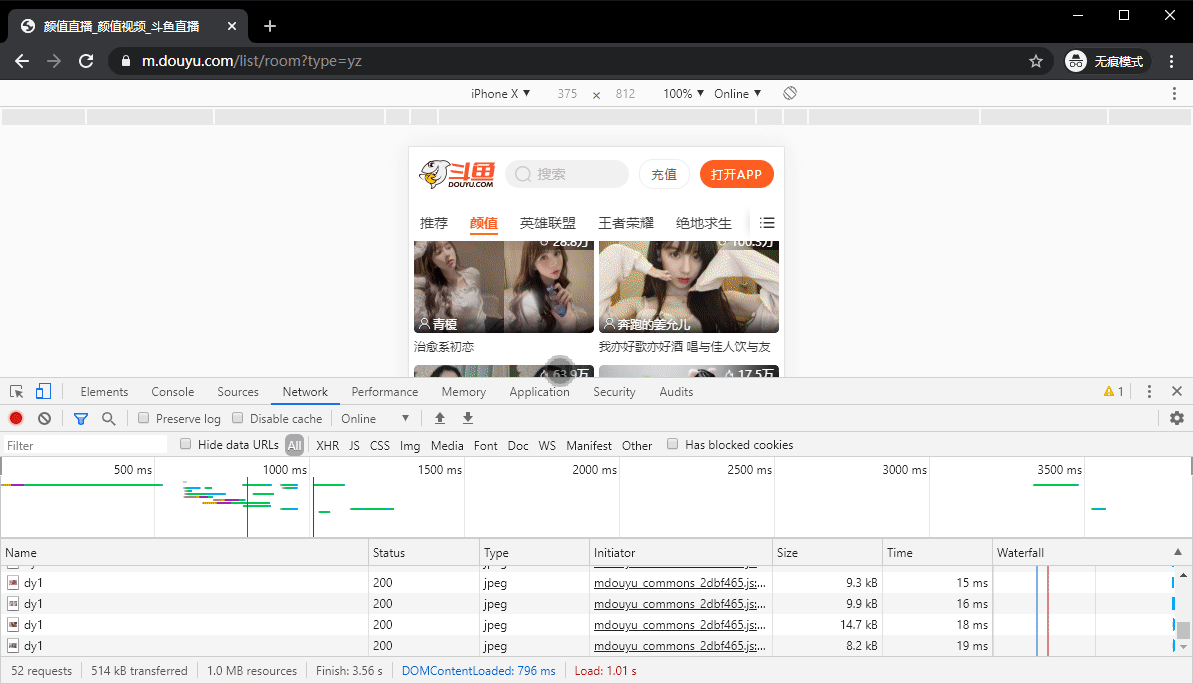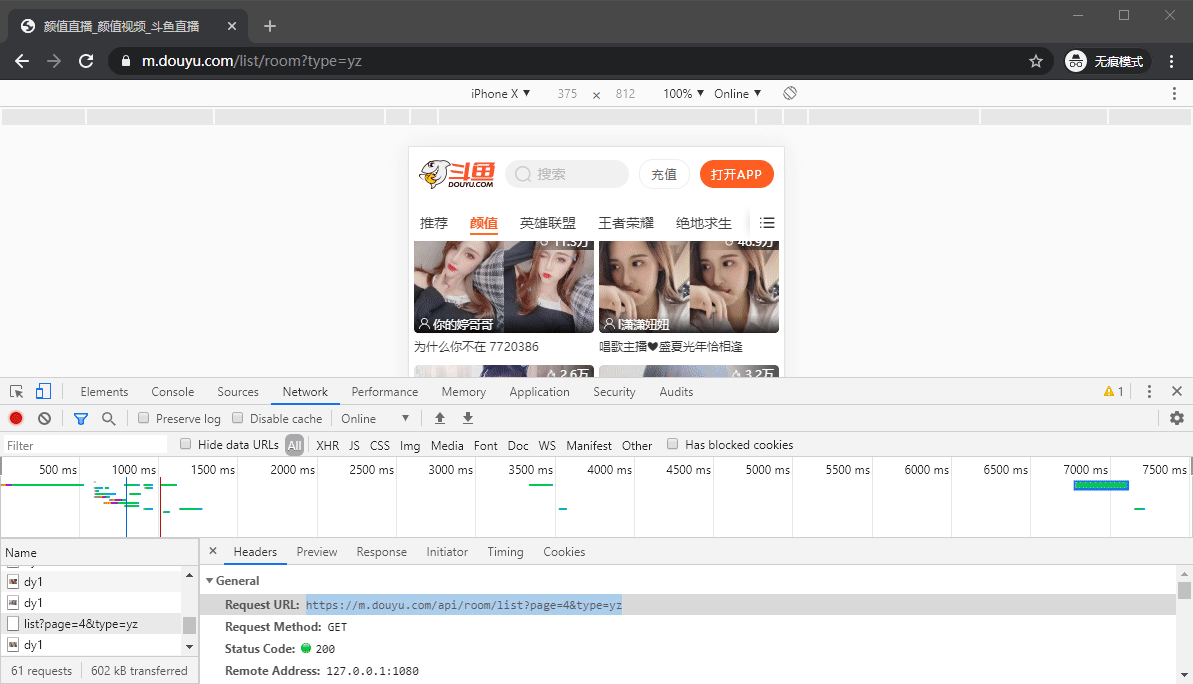
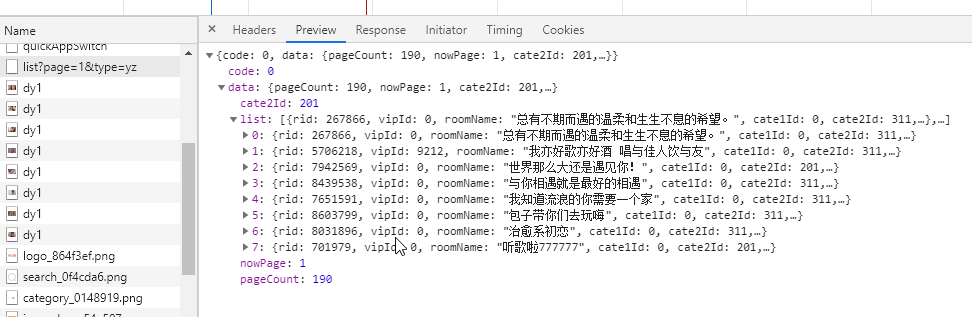
经查看可以发现,一个请求可以获取到8条内容
当然也可以通过抓包的方式获取手机端app的URL,这里不予演示,直接给出地址: http://capi.douyucdn.cn/api/v1/getVerticalRoom?type=yz&limit=20&offset=
通过接口我们可以发现要爬取的字段名称是nickname和ertical_src
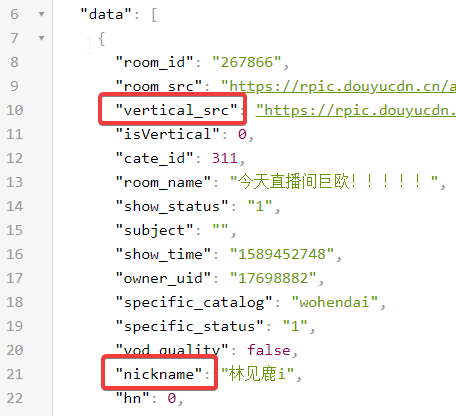
所以要去修改items.py,以得到我们想要的字段
1 | import scrapy |
接下来就是新建一个爬虫文件,取名为douyu_yz,并修改相关内容
1 | import scrapy |
注:这里由于要爬取的信息比较多,所以以变量的方式把URL存成集合,并使用yield关键字回传数据
再接着就是编写管道文件了,需要获取到图片文件并进行解码和重命名
1 | import os |
到这里,一个基本的爬虫项目已经完成,最后就是在settings.py中增加(修改)我们需要的配置
1 | # 配置图片文件路径 |
接下来执行scrapy crawl douyu_yz以进行爬取
可能会遇到的问题:
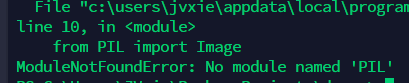
这是由于没有安装pillow库,使用pip安装即可
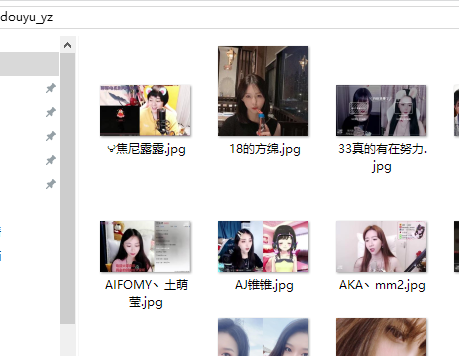
爬虫执行完成后在自定的目录中就能看到这些主播的封面图片了
 微信
微信 支付宝
支付宝

![[算法] 浅讲线段树和树状数组(一)](https://pic.rmb.bdstatic.com/bjh/cfde8718407f5f3bc0e2a652e50705ff.png)

![[算法] 浅谈莫比乌斯反演](https://ae01.alicdn.com/kf/Hca3693487f744ad4b0a75856e314aa76K.png)
![[题解] 头脑风暴专题](https://ae01.alicdn.com/kf/Hee2a7a6730c54787a8a6184a57d7ff44s.jpg)